Solution
Semantex provides AI-powered Content Intelligence leveraging APIs that enable you to assess a content component, document, or even store and analyze your entire content set over time.
Document Parsing
- Content extraction
- Paragraph clustering
- Metadata extraction
- Custom import
Document Enrichments
- Language detection
- Address detection
- Salutation
- Header detection
- Footer detection
- Table detection
- List detection
Natural Language Processing (NLP)
- Paragraph detection
- Language detection
- Part of speech tags
- Entities
- Dependency parse trees
- Coreference resolution
- Multi- lingual and cross-lingual
Content Search
- Syntactic algorithms
- Semantic algorithms
- Multi- lingual and cross-lingual
Content Similarity
- Syntactic matching algorithms
- Semantic matching algorithms
- Multi- lingual and cross-lingual
Content Enrichments
- Language detection
- Readability
- Sentiment
- Brand compatibility
- Sentence splitting
- Multi-lingual sentence embeddings
- Machine translation
- Spell/Grammar check
- Multi- lingual and cross-lingual
Semantex APIs
Semantex Content Intelligence services are available through APIs that may be used alone or combined to support your unique use case.

Content AI
The Content AI APIs can be used to perform one-off analyses on individual content components to support a variety of requirements such as ensuring compliance, content consistency, reading levels, brand adherence, appropriate sentiment and more.

Document Parsing
The Document APIs support parsing individual PDF or Word documents into logical content components, such as address blocks, paragraphs, headers, footers, tables, bulleted sections, etc. Breaking down your communications and documents into their component parts prepares them for analysis, optimization, and transformation.
Content Hub
The Content Hub supports projects or applications requiring the processing and analysis of multiple documents, such as when identifying same or similar blocks of text across the corpus of documents or understanding the relative health of your corpus of content with respect to its reading level, sentiment, spelling and grammar.
Why Semantex?
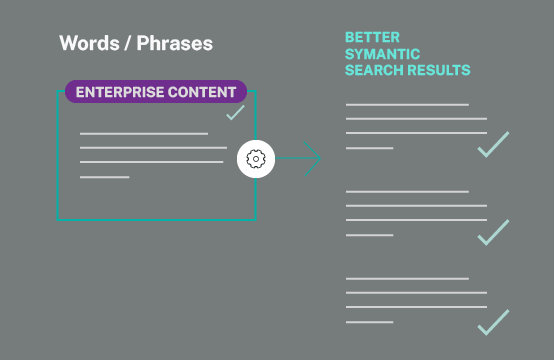
Geared for enterprise content for context and accuracy
Supports multi-lingual and cross-lingual analysis


Ultra-high scale processing
Flexible and cost-effective at any scale (from 10s to 1000s of documents)

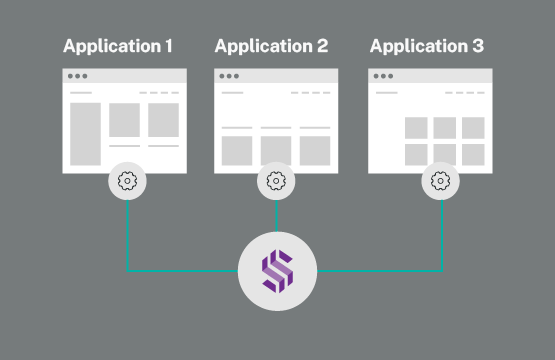
Easy and extensible integration through robust APIs
Extends existing platforms to incorporate Content Intelligence AI

Secured with a Zero Trust Strategy
With Semantex, you are in complete control of your data and access to this data. We provide state-of-the-art encryption for all data in motion and at rest. All API calls require the usage of a cryptographically strong key that ensures controlled access customizable for an individual or for a team. The transient content and document APIs work on fire-and-forget principle, whereas the content hub applications maintain data isolation using the user account boundaries.

Performance
The Semantex API platform is cloud native and is built to support a diverse set of end-user application and integration scenarios. The platform provides elastic scalability and therefore adapts to the runtime needs of both large (thousands of documents with hundreds of thousands of text content) to small (processing of individual text) applications in real-time. The cloud native footprint also ensures a high degree of service availability across multiple geographic regions.
Learn about the common use cases where Semantex tackles
some of the toughest content-related challenges.